
How do dat:// sites interact with servers?
June 10, 2018. @pfrazee
By default, sites and apps built on dat:// don’t use servers. When someone visits the app, they connect to the peer-to-peer swarm and download the app’s files directly from peers on the network.
When an app needs to do something like store data or manage a user’s profile, it can use Beaker’s DatArchive APIs to write data directly to itself, or to another dat:// website. This allows apps to manage data without ever connecting to a backend host. This is convenient and quite powerful! But in some cases dat:// sites still need to interact with servers.
In this post, I’ll describe some of the challenges related to dat:// apps interacting with servers, and share some thoughts about how Beaker might approach those challenges.
1. Cross-origin resource sharing (CORS)
Cross-origin resource sharing (CORS) is a policy that prevents a webpage from connecting to a server, unless that server has given that webpage permission to connect. It’s a sensible policy on a server-based Web, but it presents a unique challenge for building apps with dat://.
A webpage can access its own host server, but can’t access any other server. That’s not a blocking problem on the HTTP Web, because on http:// your hosting server can make the request on behalf of your webpage.
So, while this is typically not possible:
foo.com/index.html ---GET---> bar.com/data.json
You can solve it by routing the request through your host server:
foo.com/index.html ---GET---> foo.com ---GET---> bar.com/data.json
In dat:// sites, there is no host server, so that’s not possible! There’s no server to route the request through.
We’re approaching this challenge by adding an experimental API (experimental.globalFetch) to Beaker 0.8:
var res = await experimental.globalFetch('https://example.com')
var body = await res.text()
This API is functionally identical to fetch, with the following caveats:
- CORS is not applied, so the site can send a request to any service
- A permission prompt is raised for each request to a new origin
- Currently only
HEADandGETare supported - Cookies/credentials are never sent
For each new origin that the site contacts, a permission prompt will be presented:
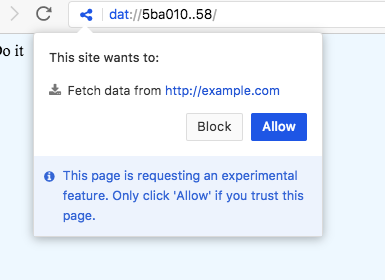
This makes it possible for dat:// apps to make cross-origin requests, while the user still has an opportunity to block the requests.
We’ll have this documented once Beaker 0.8 final is released.
2. Service configuration with PSA
Sometimes dat:// apps interact with services like Hashbase or Homebase to provide extra functionality that the p2p network can’t. We think it’s important that apps don’t hard-code the services they use, but instead allow the user to configure their choice of preferred service.
So how do we ensure that users can choose which services they use, and unbind service choice from the application interface?
This question also applies to Beaker’s builtin interfaces. Pinning tools like Hashbase and Homebase help keep dat:// sites online, and since they’re an important part of p2p Web workflows, we want to build interfaces in Beaker that help the user connect to them, but we don’t want to hardwire any one service into Beaker.
To solve this, we created the Public Service Announcement (PSA) discovery protocol. PSA enables Beaker to discover and integrate with any service that adheres to a PSA. For the pinning services, we use PSA to discover services that adhere to the DEP-0003: HTTP Pinning Service API.
It’s a very straight-forward protocol. A service using PSA hosts a json document at /.well-known/psa that looks like this:
{
"PSA": 1,
"title": "My Example Service",
"description": "Demonstrates the PSA service document",
"links": [{
"rel": "http://api-spec.com/address-book",
"title": "Example.com's User Listing API",
"href": "https://example.com/v1/users"
}, {
"rel": "http://api-spec.com/clock",
"title": "Get-current-time API",
"href": "https://example.com/v1/get-time"
}]
}
All this document does is declare what APIs the service provides. It’s structured like many other Web standards, using links and rel-types to identify resources. We’re using it in Beaker to provide builtin interfaces for pinning (work in progress).
{kind=link}
Using PSA to provide server selection for apps
The PSA protocol has utility outside of Beaker’s own UIs.
Imagine if the the browser acted as a matchmaker between Web services and applications. An application could ask the browser for a service – for instance, a “TODO lists service” – and a modal could open, prompting the user to choose from their existing accounts.
This could lead to Web APIs a like this:
var endpoint = await services.selectService({
rel: 'https://specs.com/todo-list-v1', // the rel-type of the API we need
suggestion: 'https://todo-lists.com' // suggest this service to the user
})
await endpoint.fetch({
method: 'POST',
path: '/list/1',
body: {
text: 'Make a cool TODO list api',
completed: false
}
})
The endpoint.fetch() method would operate relative to the API endpoint. Behind the scenes, the request would be sent to somewhere like
POST https://todo-lists.com/api/v1/todos/list/1
This is convenient for the developer and useful for the user. It gives the user an opportunity to choose which service is being used, and possibly change their decision later.
Managing service accounts and permissions
Server selection isn’t the only challenge. Almost all services require user accounts, and users can often have multiple accounts with a given service.
The situation is similar to OAuth flows. We want to give permissioned access to an API without exposing the login credentials. The difference is that we’re running apps which are contained inside the browser’s sandbox, rather than apps that live on their own unconstrained servers.
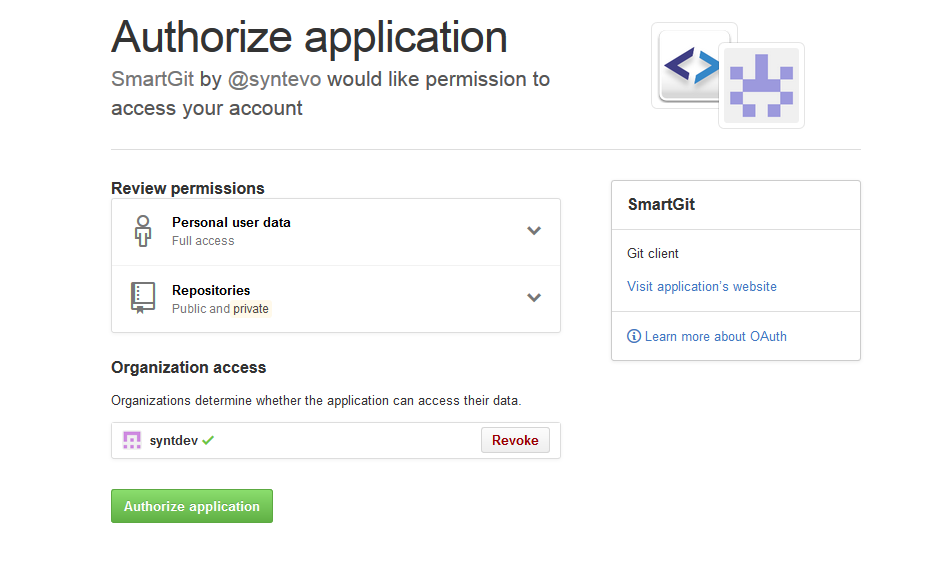
I haven’t landed on the final solution for this yet, but I like what OAuth’s UX does.
First: The browser’s service selector tool would handle the account login for the app. Credentials would never be given to an app that consumes a service.
Second: For permissioning, we could use permission prompts from the service, similar to the above OAuth flow.
Permission management for PSA
Permission management for PSA would be similar to how CORS is enforced. Because the app is running inside the browser sandbox, we can trust the browser to manage access and to render permission prompts on behalf of the server. All we need is for the server to tell us what permissions exist, and when to ask the user to permit them.
Here’s a speculative idea of how this might be done. Similar to the Origin header in CORS, the browser would include a header specifying that the requester is a Web application accessing the service through the browser’s PSA system. Something like:
PSA-Context: website
This header says, “This is an untrusted app asking to use your APIs!”
The service could just allow the request to go forward. Arguably, by selecting the service in the PSA prompt, the user has given the app permission to leverage it freely.
However, if the app wants to give the user a chance to review what permissions are being given, it could respond with a 403 Forbidden and a JSON document describing a permission prompt.
That JSON might look like this:
{
"permissions": [
{
"id": "read-todos",
"title": "Read TODO items",
"description": "Read access"
}
{
"id": "manage-todos",
"title": "Add and edit TODO items",
"description": "Write access"
}
]
}
The browser would render this in a trusted UI. If the user accepts the prompt, the browser would resend the request with a new header:
PSA-Context: website
PSA-Permissions: read-todos+manage-todos
And the service would read the PSA-Permissions header and allow the request to proceed.
Moving forward
So far, only the experimental.globalFetch Lab API has been merged into Beaker master branch.
We might soon add an experimental.services Lab API as well. The permissioning protocol (PSA-Context and PSA-Permissions headers) would need a little more thought before moving forward.
The purpose of a Lab API is to move quickly. Any time we add an API under experimental.*, we’re saying “this API is not stable and will almost certainly go away.” We create Lab APIs so that we can run experiments or provide short-term solutions.
The APIs described in this post are designed to solve problems that are unique to applications built on the p2p Web, and/or to give users more flexibility in managing their online experiences. We’ll see how well they work.
Tweets: twitter.com/pfrazee
Code: github.com/pfrazee
Creating a peer-to-peer Web: beakerbrowser.com