
Achieving Scale in the Decentralized Web
December 22, 2016. @pfrazee
One of the on-going questions of decentralized tech is, how will it scale? Which is another way of saying, is it viable?
The Web has always been about scale. If we’re not able to produce Web-scale applications, then it’s time to pack up and go home. Addressing this for the P2P Web stack (Beaker and Dat) is interesting both as a technical discussion, and as an exploration of viability.
The pure P2P solution
Dat sites are mutable file archives. They are syncronized in active swarms, and each of them maintains a changelog. When there’s a write, an entry is added with the updated hash-reference for the file.
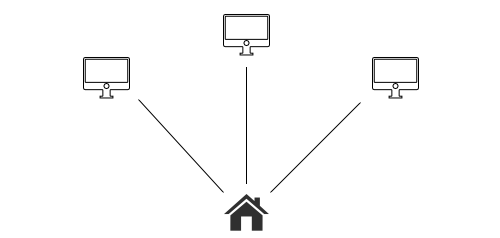
Let’s say our goal is to build a purely P2P twitter called “Fritter.” Here’s how we’ll architect it:
- Each user creates a Dat site that will represent their account.
- Users write a
/profile.jsonat the root.{"name":"bob","bio":"a cool hacker"} - To write a status update, users write a new .json to the
/statusesfolder. The name of each .json is not important. - To follow someone, users store the URL of the target’s dat-site in local storage.
- To assemble the feed-view, the app scans the
/statusesfolder of all followed sites, and assembles the found files by creation time.
To update the feed, Fritter will actively sync the followed sites. When updates are made, the sites’ files will update in the local cache. A refresh of the feed-view will get the latest view.
Does it replace Twitter?
Decidedly not. Here’s why:
- Twitter is able to inform you when any user mentions you. Fritter can’t, because Fritter only sees the messages from the followed user-sites.
- Twitter is able to assemble threads with replies from anybody in the network. Again, Fritter can’t, for the same reason. A reply by someone not followed is invisible. That becomes complicated when there are conversations with FoaFs.
- Twitter is able to show which hashtags are trending. Again, Fritter can’t.
As a purely P2P solution, Fritter is capable of a lot, but it could never be a 1:1 replacement for Twitter.
“Maybe Fritter shouldn’t try to be Twitter.” Well, maybe. But that’s not our stated goal. Our goal is to make a decentralized web that competes directly with the centralized alternative.
So, what can we do?
Aggregated views via P2P Web crawlers
Dat sites are generally like regular web-sites, except that they have much better cache & sync properties. A pure P2P app like our “Fritter” uses the Dat sites to replace its backend, and so it writes jsons to them.
The problem Fritter is having while trying to match Twitter is, a lack of global knowledge. If it were possible for each user to aggregate each other user's site, then the problem would be solved.
Of course that’s not feasible for everyone to aggregate all sites, but why not for a few crawlers?
This ends up being our solution.
As with search-engines, we can setup P2P Web crawlers to index all the sites published by users. Instead of providing only search, the services host structured views which are assembled from the .jsons published in all the different sites.
The crawlers’ views fill in the gaps in Fritter’s pure-P2P design: notifications, thread views, trending hashtags, and anything else we like.
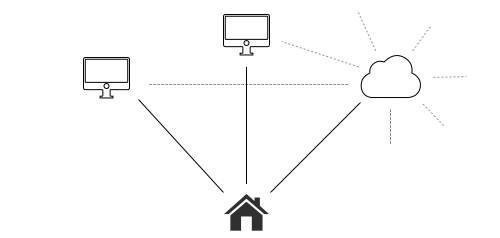
What’s effective about this design is, it retains the decentralization of the P2P Web. These crawler services produce their views by reading publicly-available sites. If somebody wants to setup a competing crawler, they have access to the exact same dataset.
There’s no walled garden for Web crawlers. Their datasets can be freely replicated from the public Web.
So the trick to this architecture is to use the dat-sites to handle all interactions that you want to be independent of a single service. If you want something to be on public record, you make the interaction by reading and writing files in a site. If you want to hide the interaction, make it with an HTTPS request.
The P2P / Service hybrid
The basic design I suggested with Fritter is exactly how you’d want to write an application. Each user should be represented by a dat-site. The dat-site URL is now the user’s ID (or one of them). The files written to the user-dat drive the user’s actions and behaviors.
Applications can use different P2P & Service hybrids to handle what they need. Fritter can exist in a purely P2P configuration, but it will lack the Twitter-like features. You can pepper in a crawler-site as a read-only source of aggregated views, and that can drive a wider view of the network.
Added bonus: this design will handle network failures elegantly, as the primary dataset is cached locally, and writes work offline.
A service which is not read-only can also be driven by this same architecture. To do this, your signup flow will include receiving the URL of the user’s dat-site, followed by a verification where you send a nonce or signed payload, and the user writes that payload to a proof file (proving ownership). Any interaction you want to make public, you drive by read/writing files on the user-dat.
This is the design we’re using for a Public Peer service; when the user writes a file about a new dat that should be rehosted, the service will sync the dat and count it against the user’s quota. The user can stop hosting by deleting the file.
I’ll continue to write about this architecture as we develop more real-world experience with it.
Tweets: twitter.com/pfrazee
Code: github.com/pfrazee
Creating a peer-to-peer Web: beakerbrowser.com